webSDM - including known trophic interactions in SDM
webSDM implements the trophic SDM model described in Poggiato et al., “Integrating trophic food webs in species distribution models improves ecological niche estimation and prediction”. Trophic SDM integrate a known trophic interaction network in SDM, thus providing more realistic and ecologically sound predictions. We here after present a quick introduction to some of the feature of the package, but we refer to the vignettes and the help functions for a more complete documentation of our package.
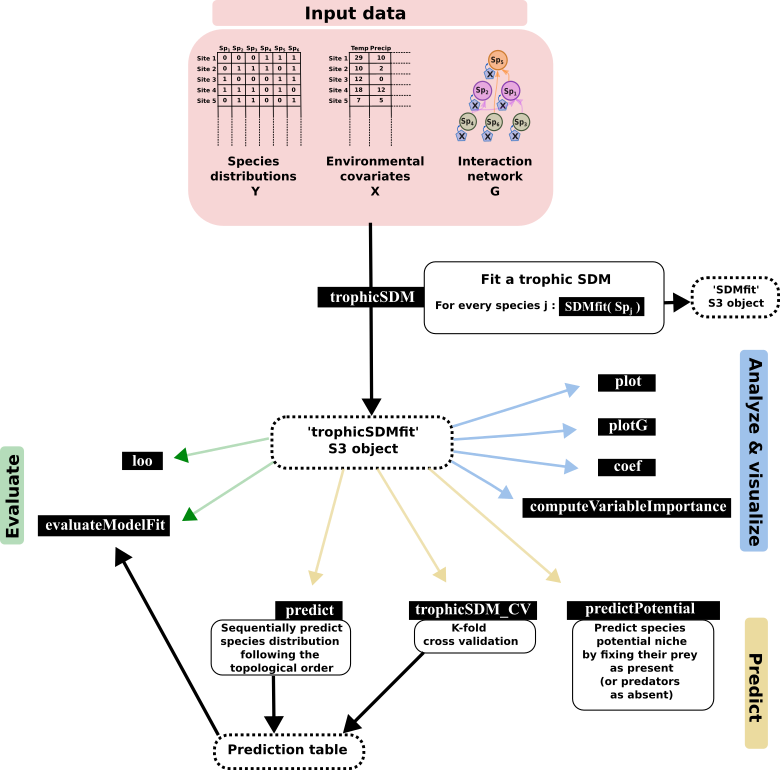
Fit a trophic SDM to data
Fitting a trophic SDM require the species distribution data, the environmental covariates and a known trophic interaction network.
We load a simulated datasets, where Y contains the species distribution data (a site x species matrix), X the environmental covariates (a sites x covariates matrix) and G is an igraph object describing the interaction network (with links going from predators to prey). We specify, for every species, a quadratic relationship with respect to the environment, and we fit a model assuming bottom-up control (i.e., predators are modeled as a function of preys). We fit the trophicSDM in the Bayesian framework.
data(X, Y, G)
m = trophicSDM(Y = Y, X = X, G = G, env.formula = "~ X_1 + X_2",
family = binomial(link = "logit"),
mode = "prey", method = "stan_glm")Inferred coefficients
We can see the formula of each glm in the argument $form.all
m$form.all
## $Y1
## [1] "y ~ X_1 + X_2"
##
## $Y2
## [1] "y ~ X_1 + X_2"
##
## $Y3
## [1] "y ~ X_1 + X_2"
##
## $Y4
## [1] "y ~ X_1+X_2+Y3"
##
## $Y5
## [1] "y ~ X_1+X_2+Y1+Y2+Y3"
##
## $Y6
## [1] "y ~ X_1+X_2+Y3+Y5"We can have a first look to regression coefficients using the function plot.
plot(m)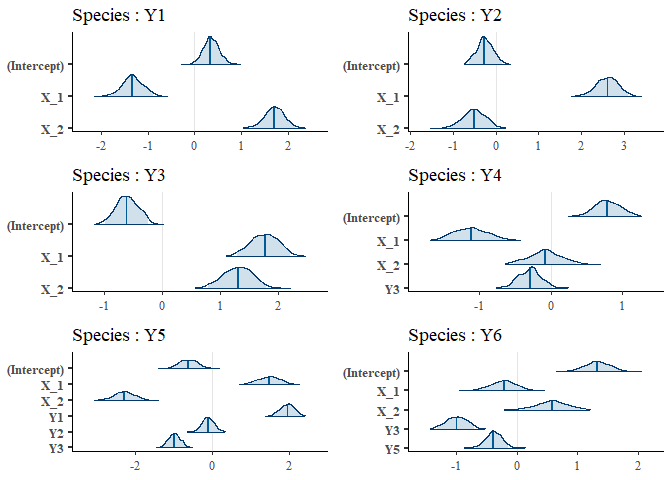
We can access to the regression coefficients (eventually standardised) with the function coef.
coef(m, standardise = T, level = 0.9)
## $Y1
## estimate 5% 95%
## (Intercept) 0.3436947 0.3436947 0.3436947
## X_1 -0.2021379 -0.2610196 -0.1437026
## X_2 0.2551022 0.1967936 0.3060621
##
## $Y2
## estimate 5% 95%
## (Intercept) -0.26667469 -0.2666747 -0.26667469
## X_1 0.38623879 0.3185228 0.44548596
## X_2 -0.07487371 -0.1398988 -0.01233344
##
## $Y3
## estimate 5% 95%
## (Intercept) -0.6087146 -0.6087146 -0.6087146
## X_1 0.2691505 0.2040072 0.3264109
## X_2 0.1959559 0.1277228 0.2558819
##
## $Y4
## estimate 5% 95%
## (Intercept) 0.78313457 0.78313457 0.783134568
## X_1 -0.17572121 -0.23117578 -0.111252286
## X_2 -0.01240440 -0.07179788 0.044998167
## Y3 -0.07121957 -0.13386056 -0.008400504
##
## $Y5
## estimate 5% 95%
## (Intercept) -0.6183171 -0.61831706 -0.6183171
## X_1 0.2012124 0.13693977 0.2583883
## X_2 -0.3040676 -0.36413006 -0.2482235
## Y1 0.4429577 0.37314154 0.5052524
## Y2 -0.0238899 -0.08046871 0.0309484
## Y3 -0.2091481 -0.26014005 -0.1566986
##
## $Y6
## estimate 5% 95%
## (Intercept) 1.32269012 1.32269012 1.32269012
## X_1 -0.03325986 -0.09097127 0.01820810
## X_2 0.08919394 0.02389159 0.15177465
## Y3 -0.24024322 -0.30943078 -0.17621452
## Y5 -0.09973197 -0.15640795 -0.04450875We can visualise the biotic coefficients with the function plotG_inferred
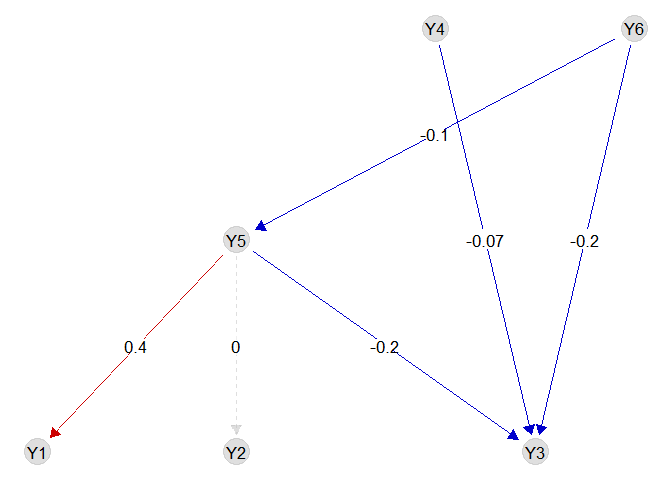
We can also visualise the importance of each (set of) variable with the function `computeVariableImportance’
VarImpo = computeVariableImportance(m,
groups = list("Abiotic" = c("X_1","X_2"),
"Biotic" = c("Y1","Y2", "Y3", "Y4", "Y5", "Y6")))
VarImpo = apply(VarImpo, 2, function(x) x/(x[1]+x[2]))
tab = reshape2::melt(VarImpo)
tab$Var2 = factor(tab$Var2, levels = colnames(Y))
ggplot(tab, aes(x = Var2, y = value, fill = Var1)) + geom_bar(stat="identity") +
theme_classic()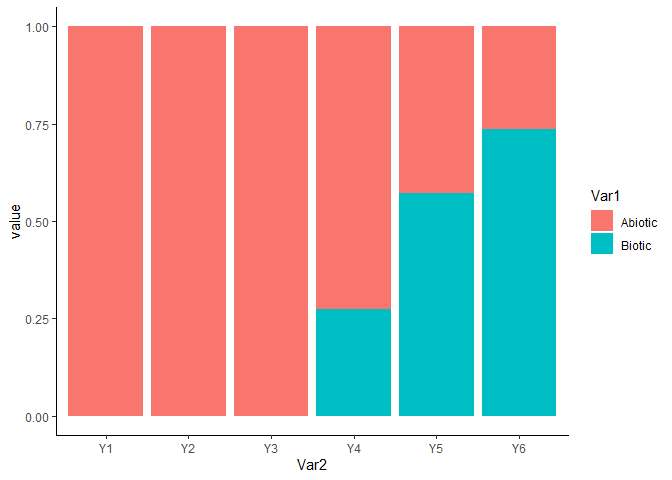
Local objects
We can access each local model in the field $model and then select a given local model, that can be analysed using some the implemented methods
m$model$Y5
## ==================================================================
## Local SDMfit for species Y5 with no penalty , fitted using stan_glm
## ==================================================================
## * Useful S3 methods
## print(), coef(), plot(), predict()
## $model gives the stanreg class object
## ==================================================================Predictions
We can predict with a fitted trophic SDM in multiple ways. The most straightforward way is to use the function predict. We can for example obtain 50 draws from the posterior predictive distribution of species (pred_samples = 50) using predicted presence-absences of species to predict their predators (prob.cov = TRUE). When we don’t specify Xnew, the function sets Xnew = X by default. We can thus obtain the fitted values of the model and compute goodness of fit metrics. Notice that other metrics like AIC or loo are also available.
Ypred = predict(m, fullPost = FALSE, pred_samples = 50, prob.cov = FALSE)
# predict returns a list contaning for each species the predictive samples at each site
# But since we specified fullPost = FALSE it only give back the predictive mean and quantiles
Ypred = do.call(cbind,
lapply(Ypred, function(x) x$predictions.mean))
Ypred = Ypred[,colnames(Y)]
evaluateModelFit(m, Ynew = Y, Ypredicted = Ypred)
## auc tss species
## 1 0.6733574 0.28064516 Y1
## 2 0.7048959 0.31015078 Y2
## 3 0.6690035 0.27931242 Y3
## 4 0.5988342 0.17092061 Y4
## 5 0.6236528 0.20786045 Y5
## 6 0.5581631 0.09940342 Y6
m$log.lik
## [1] -3638.686
m$AIC
## [1] 7337.373
loo(m)
## [1] -3650.931We can also evaluate the quality of model predictions using K-fold cross-validation:
CV = trophicSDM_CV(m, K = 3, prob.cov = T, run.parallel = FALSE)
# Transfom in a table
Ypred = CV$meanPred
# Re order columns
Ypred = Ypred[,colnames(Y)]
evaluateModelFit(m, Ynew = Y, Ypredicted = Ypred)We can now evaluate species probabilities of presence for the environmental conditions X_1 = 0.5 and X_2 = 0.5.
Pred = predict(m, Xnew = data.frame(X_1 = 0.5, X_2 = 0.5), fullPost = F)
t(do.call(cbind, Pred))
## predictions.mean predictions.q025 predictions.q975
## Y1 0.6275369 0.5919506 0.6673241
## Y2 0.6811964 0.6555955 0.7031938
## Y3 0.7187342 0.6891241 0.7377668
## Y4 0.4978676 0.4544304 0.5767335
## Y5 0.3806087 0.0963942 0.7238955
## Y6 0.6484422 0.4698095 0.8539271We can also obtain an estimation of the potential niche, that corresponds, in the bottom-up approach, to the probability of presence of a species given that its preys are present. We can for example compute the probability of presence of species for the environmental conditions X_1 = 0.5 and X_2 = 0.5 assuming all their preys to be present.
Ypred = predictPotential(m, fullPost = FALSE, pred_samples = 100, Xnew = data.frame(X_1 = 0.5, X_2 = 0.5))Frequentist approach
Notice that we can also fit a trophic SDM in the frequentist approach.
m = trophicSDM(Y = Y, X = X, G = G, env.formula = "~ X_1 + X_2",
family = binomial(link = "logit"),
mode = "prey", method = "glm")All the above-mentioned functions are also available in the frequentist framework, with adaptations when necessary (e.g. coefficients are significant or not depending on the p-values instead of the credible interval). However, error propagation is not available and we can only obtain one prediction for each species and site, instead of multiple samples in the Bayesian case.
Penalisation
We can infer a sparse model by specifying penal = "horshoe" if we set method = "stan_glm" (i.e. in the Bayesian framework), or penal = "elasticnet" if we set method = "glm" (i.e. in the frequentist framework).
m = trophicSDM(Y = Y, X = X, G = G, env.formula = "~ X_1 + X_2",
family = binomial(link = "logit"),
mode = "prey", method = "glm", penal = "elasticnet")
m = trophicSDM(Y = Y, X = X, G = G, env.formula = "~ X_1 + X_2",
family = binomial(link = "logit"),
mode = "prey", method = "stan_glm", penal = "horshoe")Composite variables
We can include composite variables using the arguments sp.formula and sp.partition. We refer to the vignette ‘Composite variable’ for an exhaustive description of these arguments and how to use them to obtain any kind of model specification. For example, we can model species as a function of of their prey richness.
m = trophicSDM(Y = Y, X = X, G = G, env.formula = "~ X_1 + X_2",
sp.formula = "richness",
family = binomial(link = "logit"),
mode = "prey", method = "glm")
m$form.all
## $Y1
## [1] "y ~ X_1 + X_2"
##
## $Y2
## [1] "y ~ X_1 + X_2"
##
## $Y3
## [1] "y ~ X_1 + X_2"
##
## $Y4
## [1] "y ~ X_1+X_2+I(Y3)"
##
## $Y5
## [1] "y ~ X_1+X_2+I(Y1 + Y2 + Y3)"
##
## $Y6
## [1] "y ~ X_1+X_2+I(Y3 + Y5)"Author
This package is currently developed by Giovanni Poggiato from Laboratoire d’Ecologie Alpine. It is supported by the ANR GAMBAS. The framework implemented in this package is described in: “Integrating trophic food webs in species distribution models improves ecological niche estimation and prediction” Poggiato Giovanni, Jérémy Andréoletti, Laura J. Pollock and Wilfried Thuiller. In preparation.